In my previous post, I outlined the “Zero-Knowledge” mission: building a tool that can navigate the labyrinth of data broker opt-out forms without ever leaking my Personal Identifiable Information (PII) to a third-party cloud.
Since then, the project has evolved from a “numb-brain” script into a fully containerized, AI-driven microservice stack. Here is the update on how I moved from manual keyword mapping to a Sovereign Automation Stack capable of handling over 7,300 broker records.
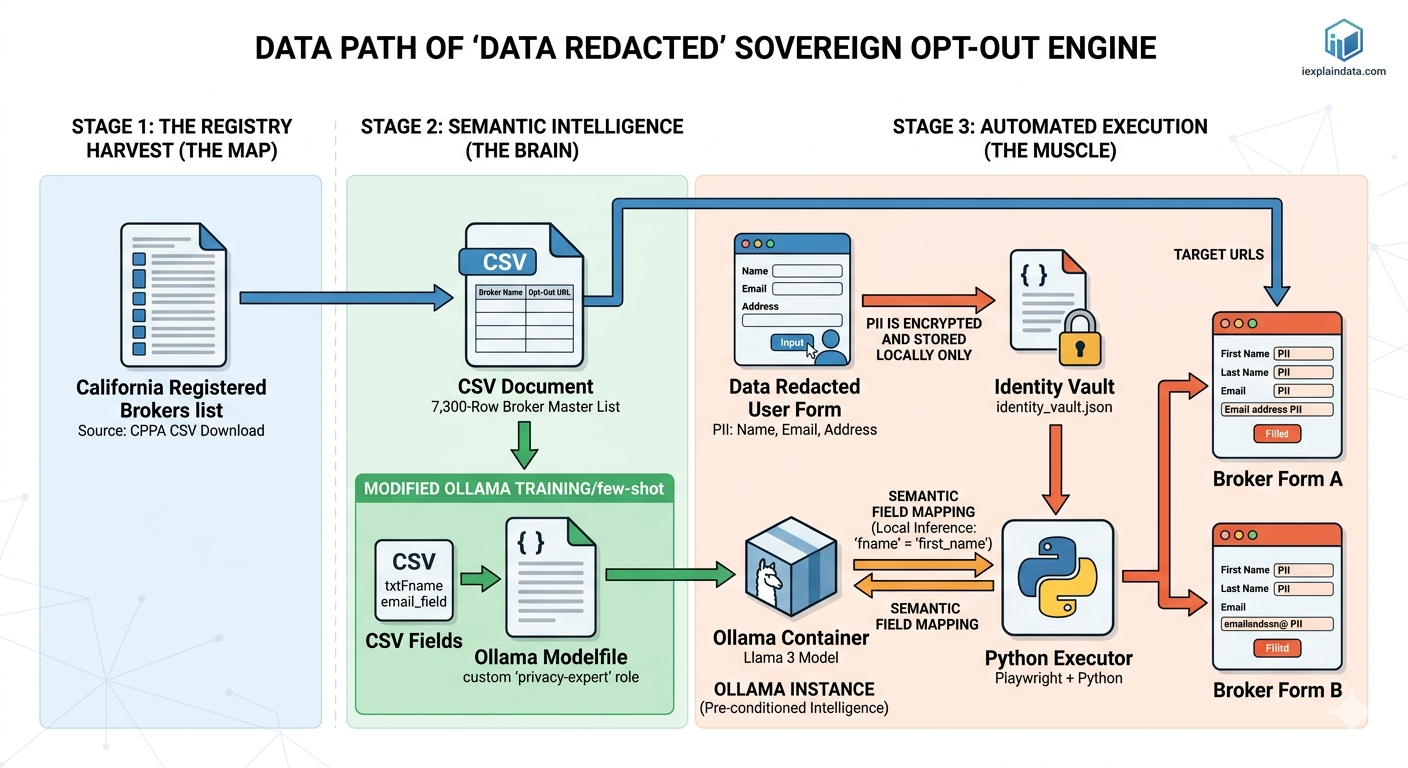
🏛️ The Architecture: Three Pillars of Privacy
To move beyond a simple Python script, I’ve migrated the project into a Three-Tier Docker Orchestration. This ensures “Environment Parity”—meaning the bot runs exactly the same on my local machine as it would on a dedicated home server.
- The Memory (MySQL): I moved the California Broker Registry from a static CSV into a containerized MySQL database. This allows for real-time “Checkpointing,” ensuring that if a crawl fails at row 2,500, the system knows exactly where to resume.
- The Brain (Ollama + Llama 3): This is the most significant leap. Instead of writing thousands of
if/elsestatements to find “First Name” fields, I’m utilizing a local instance of Llama 3. Using a custom Modelfile, I’ve “trained” the model to act as a Privacy Expert that semantically maps messy HTML labels to my local Identity Vault. - The Muscle (Playwright): A dedicated container running a “Privacy-Hardened” Chromium browser. It receives instructions from the Python executor and physically types the data into the forms.
🧠 Solving the “Numb-Brain” Mapping Problem
In my original draft, the most daunting task was the manual labor: how do you tell a bot that txt_fname_01 and Given Name both mean first_name?
By implementing Dynamic Semantic Mapping, I’ve eliminated the manual work. When Playwright lands on a broker page, it scrapes the field labels and sends them to the Ollama container. The local AI performs a “Sovereign Handshake”—it identifies the field’s intent strictly within my local RAM. My PII never leaves the “Steel Box” of the Docker network until the final moment of form submission.
🧟 The “Franken-Data” Hurdle
The scale of this project (7,300+ rows) has highlighted a disturbing reality: Data Brokers are creating “Franken-Data” versions of our identities. During testing, I found records where my identity was “stitched” to incorrect addresses or even other individuals. This isn’t just a privacy nuisance; it’s a Hirability Risk. If an automated HR screening tool pulls from a “Franken-Profile” that includes a criminal record or a failed bar exam that isn’t yours, you’ve lost the job before the interview starts.
🚀 What’s Next?
The infrastructure is live. The “Brain” is trained. The “Memory” is persistent.
The next milestone is the Full-Scale Execution: letting the Sovereign Engine loose on the complete 7,300-row registry. I’ll be monitoring the “Success/Failure” logs in the MySQL container to refine the AI’s mapping accuracy.
Cleaning your digital footprint isn’t just about hiding; it’s about Identity Integrity.